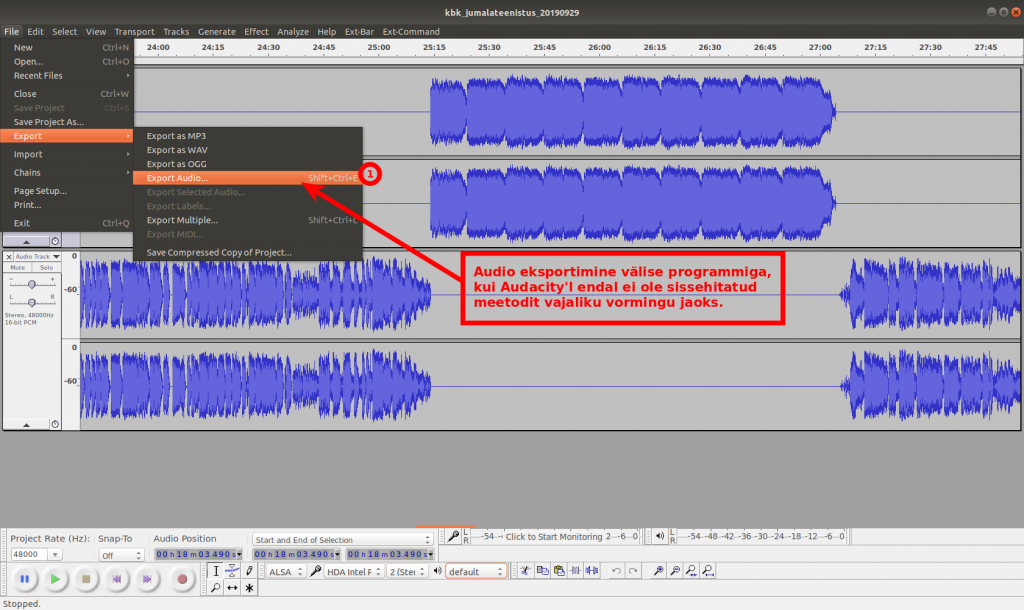
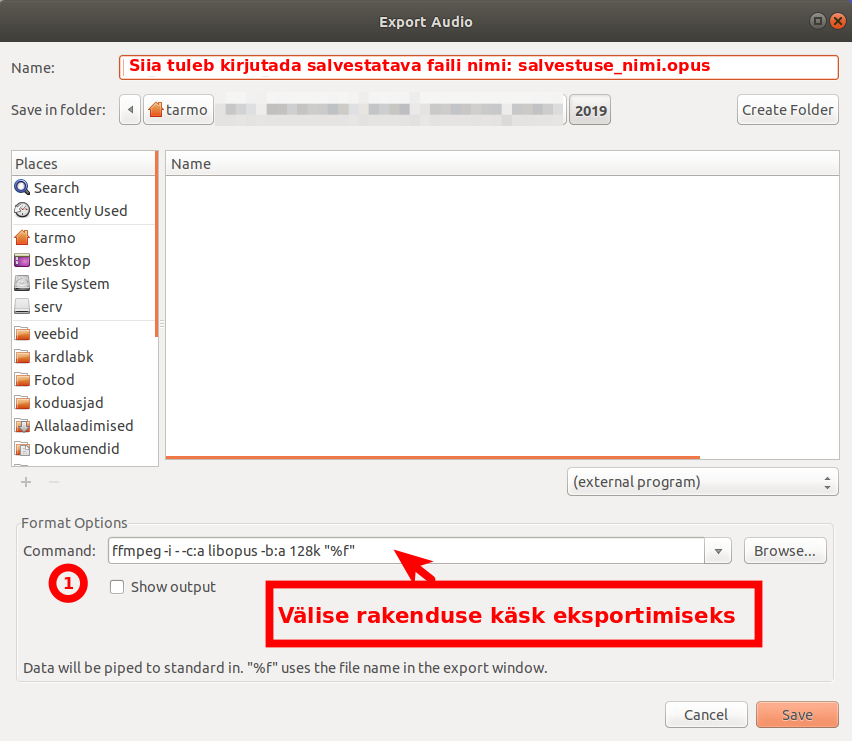
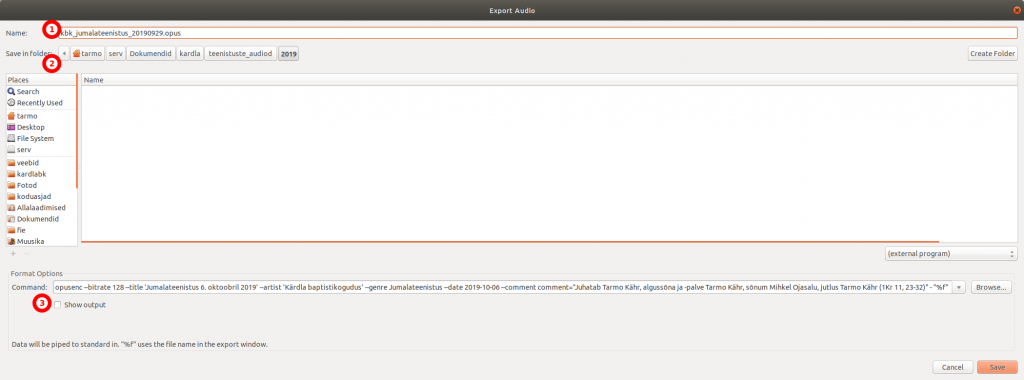
Eelmisel korral kirjutasin video loomisest, mille lähtematerjaliks oli hulk pilte. Kirjutan nüüd video loomisest uuesti – aga sel korral oli pilte palju rohkem.
Niisiis. alustame.
Algmaterjal: kaks kataloogi, kuhu kaks kaamerat tegid poole aasta jooksul iga minut ühe pildi. Pildid on samast objektist, aga erinevate nurkade all. Kaamerate piltidest tuleks kokku panna video. Pilte on kokku sadu tuhandeid (iga tund 60 pilti ja niimoodi septembrist oktoobrini (13 kuud): 60(pilti tunnis)x24(tundi päevas)x30(päeva kuus)x13(kuud)=561600 pilti ÜHE kaamera kohta). Tegelikult on see number ligilähedane, sest igas kuus ei ole 30 päeva ja aeg-ajalt oli ka häireid, nii et pilte ei saanud üle võrgu üles laadida. Piltide mõõtmed: 800x600px, ühe pildi maht ca 120kB.
Eesmärk: luua piltidest „kiirvideo“ objekti valmimise kohta.
Sammud eesmärgi saavutamiseks:
- Kopeerida vajalik hulk pilte kummagi kaamera algmaterjalide kataloogist töötlemiseks uude kataloogi. Arvestusega, et video tuleb 25 kaadrit sekundis, siis vajalike piltide arv sõltub loodava video pikkusest (iga minuti kohta 25×60=1500 pilti).
- Seejärel kleepida kaamerate pildid kokku nii, et kaks pilti oleks uuel pildil kõrvuti. Kui algsed pildid on mõõtudega 800x600px, siis kahest kokku pandud uus pilt peab olema mõõtudega 1600x600px (kõrgus jääb samaks, aga kaks korda laiem).
- Seejärel kokkukleebitud piltidest luua vajalik videofail ja lisada sinna heli.
On kaks kataloogipuud – kummlagi kaameral oma kataloogipuu. Pildid asuvad kataloogides nii, et üks aasta on üks kataloog, milles on alamkataloogid kuude kaupa. Iga kuu kataloogis on alamkataloogid kuupäevade kaupa, seal omakorda alamkataloogid tundide kaupa. Ühe tunni pildid asuvad samas kataloogis ning pildifailidel on nime algused samasugused kuni 11-nda sümbolini (faili nimes on kirjas aasta, kuu, päev, tund ja minut kahekohalisena, st AAKKPPHHMM; faili alguses on alati täht m). See pildifaili nimetamise põhimõte on läbiv kogu kataloogipuus. Niisiis, ühes kataloogis on 60 pildifaili. Kataloogipuus on aga neli taset alates tipust, kuid failinimed on ühe kataloogipuu piires kordumatud.
Näide ühe kataloogipuu kohta on alloleval pildil. Teine kataloogipuu on sarnase struktuuriga, vaid tipmine kataloog on teise nimega – lehtma.

Kataloogipuu struktuurinäide
Vaja oli leida kummastki kataloogipuust samadel kellaaegadel tehtud pildid. Faile oli kummaski kataloogipuus 561600, kokku üle miljoni faili… Kuid kellaaega tähistas neli numbrit, mis asusid faili nimes kaheksandast kuni üheteistkümnenda positsioonini. See andis võimaluse luua kopeerimiseks vajalik reegel. Tegelikult polnud üldse vaja vaadata 11-st postitsioonist edasi, kus lõpud olid muutuvad. Minule vajaliku video jaoks piisas, kui ma võtsin igast päevast ca 10 kaadrit kindlatel kellaaegadel. Niisiis tuli mul teha ühe kataloogipuu kohta kümme kopeerimist – iga vajaliku kellaaja kohta tuli üks käsk. Kokku sai kakskümmend korda kopeerimist. Sihtkataloogid, kuhu kopeerida, tegin käsitsi enne valmis.
Käsk sai järgmine:
|
|
find . -name "???????0910*.*" -exec cp -p -t /see/uus/kataloog/kuhu/kopeerida/lehtma/ {} |
Selgitus:
- find . -name “???????0910*.*”
Otsi faile, mille nimes oleks alates 8-ndast sümbolist antud konkreetsed numbrid. Need konkreetsed numbrid viitavad kellaajale, millal pilt tehti: näites on 0910 – pildid, mis on tehtud kell 9:10. Faili lõpp pole tegelikult enam oluline ja ilmselt võiks jätta ka lihtsalt tärni. Käsk „find“ töötab rekursiivselt, niisiis alustatakse parasjagu aktiivsest kataloogist (punkt tähistab aktiivset kataloogi) ja käiakse läbi kogu kataloogipuu.
- Käivita leitud failide kopeerimine (-exec cp) ja ära muuda failide ajatempleid (-p) ning kopeeri etteantud sihtkataloogi (-t /see/uus/kataloog/kuhu/kopeerida/lehtma/). Sihtkataloogi määratlust alustasin süsteemi juurkataloogist (kaldkriips / tähistab linux’is juurkataloogi), aga vajadusel saab ka määrata suhteline tee sihtkataloogini.
- Korda antud tegevust niikaua kuni leiad vastavaid faile: {} +
- Seda käsku tuli korrata iga soovitud kellaaja kohta, muutes vaid 8-ndast kuni 11-kohani asuvaid numbreid.
Minul tekkis kummassegi kataloogi (lehtma ja otikas) üle 5000 faili.
Siis tuli leida veel kataloogide sisu võrdlemise teel failid, milledele uutes loodud kataloogides polnud vastet teises kataloogis. Vastavust mitteomavad failid tuli teisest kataloogist kustutada. Asi oli selles, et kaamerad ei saanud alati täpselt samadel aegadel pilte tehtud – kas võrgu ülekoormatuse tõttu või mõnel muul juhuslikul põhjusel. Seetõttu tekkis kataloogides failide kellaaegades erinevusi. Minule oli aga väga oluline saada alati kaks pilti, mis on tehtud sama minuti sees. Erinevuse kindlaks tegemiseks ja kustutamiseks kasutasin linuxis käsurea skripti:
|
|
for file in `ls otikas` ; do ls lehtma/${file:0:10}*.jpg >/dev/null 2>/dev/null if [ $? -ne 0 ] ; then echo "fail otikas/$file on, lehtma/$file puudub" rm otikas/$file fi done |
Selgitus:
- Kataloogi „otikas“ failide loetelu
- Võrdle seda loetelu kataloogis „lehtma“ olevata failide nimede esimese 11 sümboliga (arvuti alustab loendamist nullist, seetõttu 0:10, MITTE 1:11)
- Kui tulemus ei ole 0 (st failil vastavus puudub), siis anna sellest teada (echo…)
- Kustuta see fail kataloogist „otikas“ ära
Sama käsk tuli anda ka teise kataloogi suhtes.
Jäi veel mingi väike osa faile, mida see käsk ei suutnud üles leida ja kustutada, kuna osadel failidel oli mitu vastavust (skript leidis need, kus oli VÄHEMALT ÜKS vastavus, seega MITME vastavusega faile ei kustutatud. Need failid leidsime üles tabelarvutuse abil kasutades järgnevaid funktsioone:
| lehtma |
otikas |
eraldus1 |
eraldus2 |
vordlus |
| m120909091001952.jpg |
m120909091045997.jpg |
=LEFT(A2;11) |
=LEFT(B2;11) |
=IF(C2=D2;1;-1) |
Nende valemite tulemus oli selline:
| lehtma |
otikas |
eraldus1 |
eraldus2 |
vordlus |
| m120909091001952.jpg |
m120909091045997.jpg |
m1209090910 |
m1209090910 |
1/-1 |
Nüüd eksportisin mitteklappivate failide nimed csv tekstifaili. Ja nüüd sain juba linuxis anda uuesti käsu, mille abil tekstifailis olevate failide nimed sai omakorda kustutada:
|
|
cat kustutada_otika_kataloogist.csv | xargs echo rm | sh |
Failis „kustutada_otika_kataloogist.csv“ olid kustutamiseks mõeldud failide nimed.
Käsuga xargs saab luua käske, kasutades sisendina tekstifaili sisu.
Selle kohta leidus info siin: http://stackoverflow.com/questions/5142429/unix-how-to-delete-files-listed-in-a-file
Lõpptulemusena sain kaks kataloogi, kus sees oli võrdne arv pilte, mis pealegi on tehtud kõik samadel minutitel (kummaski kataloogis on igale pildile teises kataloogis samal ajal tehtud pildi näol vaste).
Veel oli vaja üle kontrollida, kas kõigi piltide mõõtmed ikka olid kindlalt samad. Kuna mul oli vaja pilte mõõtudega 800x600px, tuli leida, kas ei ole juhtumisi valedes mõõtudes pilte ja need tuli viia õigesse mõõtu. Valedes mõõtmetes pilte oli 531 (ühe kaamera esimeste kuude pildid olid liiga suured). Need viisin õigesse mõõtu programmiga phatch (http://photobatch.stani.be/).
Seejärel nimetasin mõlemas kataloogis kõik pildifailid ümber nii, et tekiks järjekord:
|
|
ls *.jpg | gawk 'BEGIN{ a=0 }{ printf "mv %s pilt_%06d.jpg\n", $0, a++ }' | bash |
Selgitus:
Oluline osa on
|
|
mv %s pilt_%06d.jpg\n", $0, a++ |
– siin antakse käsk pildifaili ümbernimetamiseks. %06d määrab kasutatava numbrikohtade arvu, minul siis 6 numbrikohta.
Tuletame nüüd veelkord meelde: sadamas oli üleval kaks kaamerat, mis mõlemad tegid sünkroonis pilte. Kummagi kaamera pildifailid said eelpool näidatud viisil välja valitud ja õigetesse mõõtudesse viidud. Praeguseks on siis kummagi kaamera pidid eraldi kataloogides ja valmis edasiseks töötluseks.
Seejärel oli aga vajadus panna kaamerate pildid kokku üheks pildiks, et tekiks „laiekraanvideo“ – niimoodi sai näidata ühes kaadris poole laiemat ala. Selle tegevuse läheolukord oli järgmine:
Esimese kaamera pildid:
otikas/pilt_00001.jpg
otikas/pilt_00002.jpg
otikas/pilt_00003.jpg
otikas/pilt_00004.jpg
otikas/pilt_00005.jpg
Teise kaamera pildid:
lehtma/pilt_00001.jpg
lehtma/pilt_00002.jpg
lehtma/pilt_00003.jpg
lehtma/pilt_00004.jpg
lehtma/pilt_00005.jpg
ja nii edasi, kummaski kataloogis oli ca 5300 pilti.
Nüüd oli vaja lahendust, mis hakkaks järjest katalooge läbi käima ja võtma paarikaupa kataloogidest pilte ja neid kokku kõrvuti panema ning tulemust salvestama kolmandasse kataloogi. Selleks saab kasutada käsku „montage“ (ImageMagick’u käsureavahend), millele tuli lihtsalt ette anda loend õigel viisil. Selleks sai tehtud järgmine skript:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
#!/bin/bash for q in `seq 0 2`; do for w in `seq 0 9`; do for e in `seq 0 9`; do for r in `seq 0 9`; do #Siia alla tuleb montage käsk nr=00$q$w$e$r echo $nr montage -tile 2x1 -geometry +1+1 lehtma/pilt_$nr.jpg otikas/pilt_$nr.jpg kataloog3/k6rvuti_$nr.jpg #Lõpetab programmi 5300 peal - kirjutada see number, kui palju on pilte if [ $nr -eq 05300 ] then exit fi done done done done |
Peale seda käsku oli mul uus kataloog (kataloog3), kus oli 5300 pilti, mis olid valmis laiekraani video tegemiseks.
Ning siis programmiga ffmpeg sai piltidest video „kokku keevitatud“:
|
|
ffmpeg -f image2 -i "pilt_%06d.jpg" -r 25 -s 800x600 -qscale 12 -an "output4.mov" |
Video tegemise õige vahend on tegelikult avconv – ffmpeg on tegelikult juba vananenud vahend ja alles veel lihtsalt ühilduvuse mõttes. Tulevastes distributsioonides kaob see ära.
Tulemusvideot saab vaadata siin: http://www.youtube.com/watch?v=98AMX3YK2BA
Antud kirjelduses ei ole toodud muusika lisamist videofailile. Muusika lisasin valmis “tummfilmile” programmiga “OpenShot video editor”.