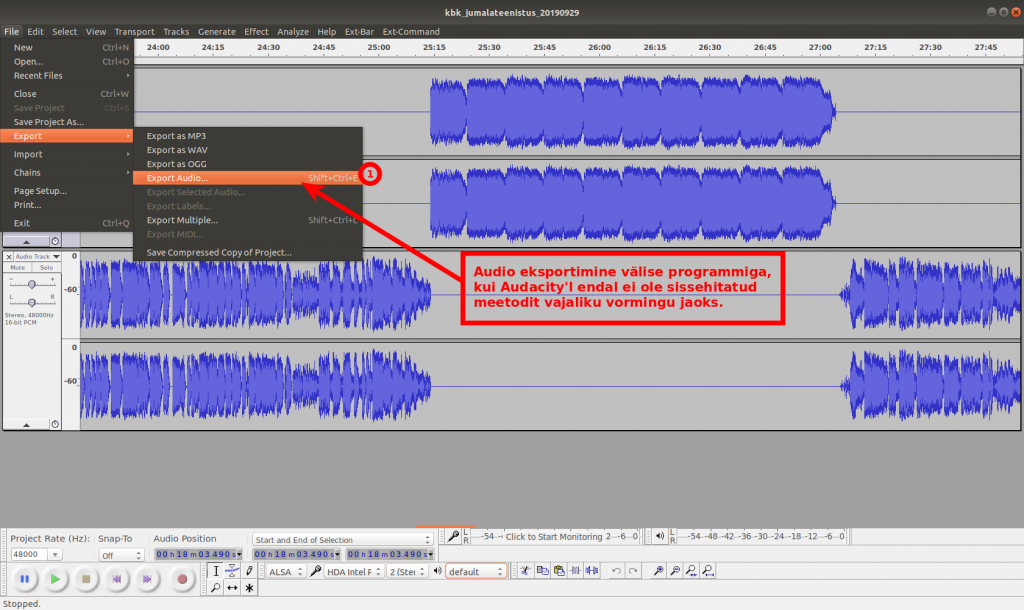
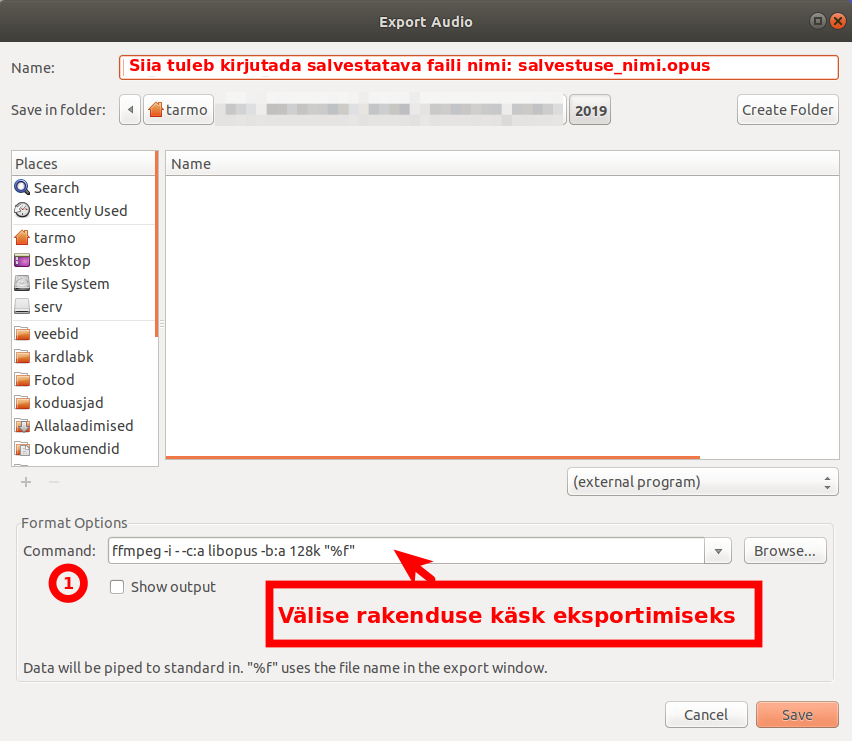
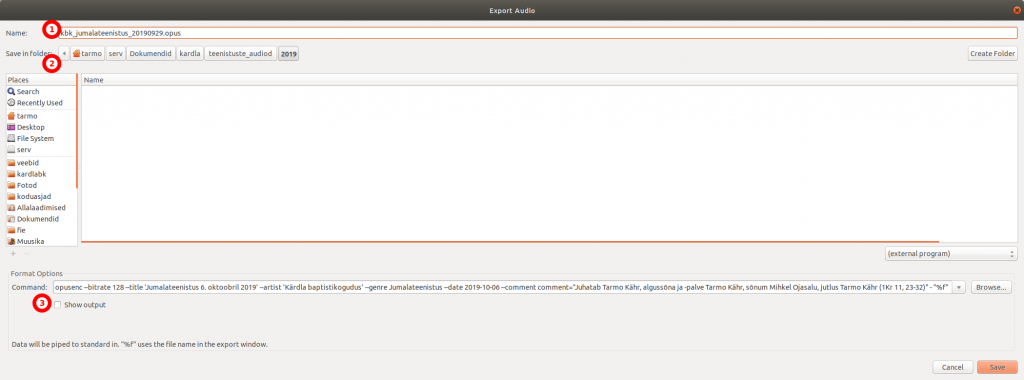
Üks sõber soovis, et ma teeksin talle kindla sisuga cd-plaadi. Üldiselt ei ole ju audiofailide plaadile kirjutamine eriti mingi probleem. Suurem jagu CD/DVD kirjutamise tarkvarasid oskavad üsna automaatselt luua vajalikud vormingus plaate.
Minul konkreetselt oli vaja luua tavaline CD-plaat, mida saaks mängida ükskõik millises (ka vanemat tüüpi) cd-mängijas. Algmaterjaliks olid arvutis olevad erinevat sorti – enamasti küll mp3 kodeeringus – failid.
Eesmärk oli saada CD-plaat, mis sisaldaks korrektseid lugude pealkirju ning lisaks soovisin luua ka plaadil olevate lugude nimekirja paberil, mida CD-karbile vahele panna.
Plaadi enda loomine ei olnud just keeruline. Kuna kasutan Ubuntu Linux arvutit, siis on minul välistatud kõik need programmid, millega sellist asja Windows-maailmas tehakse. Samas oli ikkagi valida mitme erineva CD-kirjutamise tarkvara vahel – ja mina polnud ammu ühtki plaati teinud ja enam suurt ei mäletanud. Päris hea artikkel erinevate CD-kirjutamise programmide kohta (inglise keeles) on aadressil http://www.techdrivein.com/2011/03/9-good-cd-and-dvd-burning-tools-for.html. See on küll küllaltki vana – aastast 2011 – kuid samad programmid on praegugi olemas ja väga head.
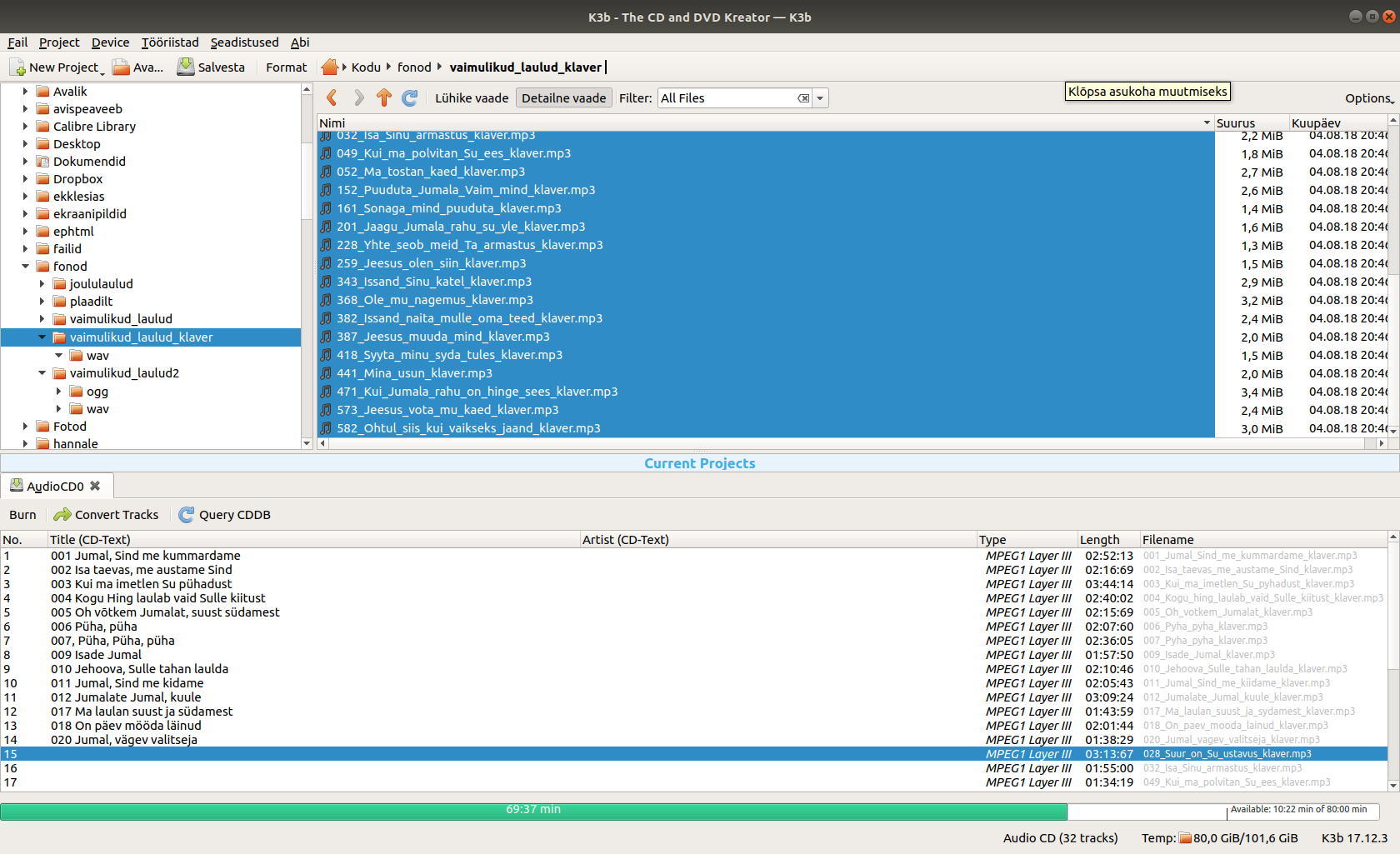
Üldiselt on Linux-maailmas nii, et igaüks peab ise endale selgeks tegema, milline vahend on tema jaoks parim. Mina nõustun üpris paljude arvamusega, et parim on tõesti K3B. K3B suutis ilma muid abivahendeid kasutamata kirjutamise käigus konverteerida mp3 failid tavalisele CD-le sobivateks audioradadeks, samuti oli olemas lugude sobivaks nimetamiseks mugav liides. Lisan ka ühe ekraanipildi – see võiks olla piisavalt informatiivne.
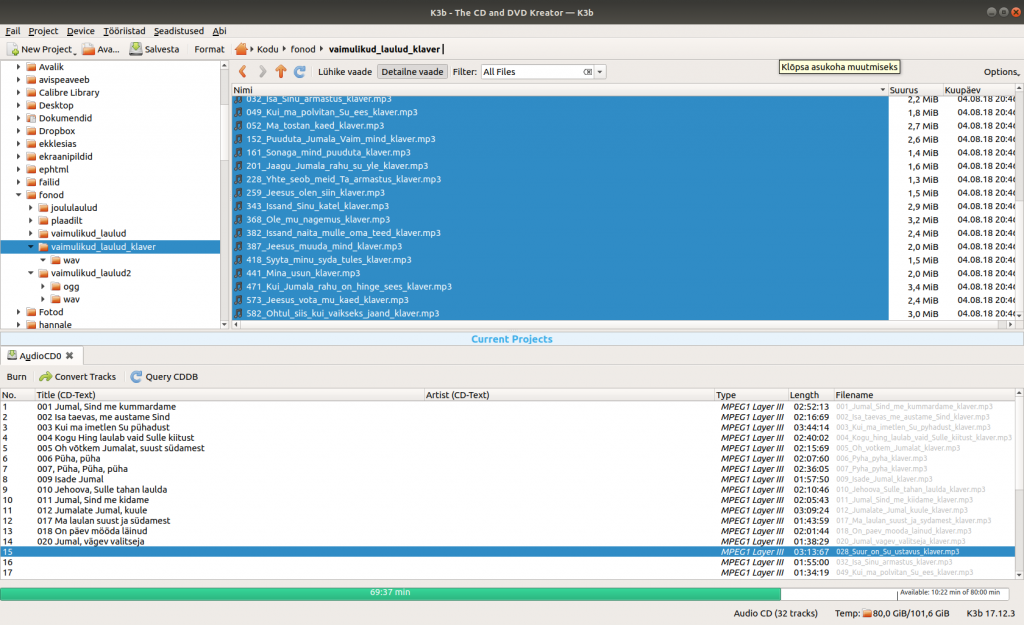
Huvitavamaks läks aga siis, kui soovisin teha plaadile juurde lugude nimekirja. Ma ei tahtnud lugude pealkirju käsitsi ümber kirjutada. Soovisin leida vahendit, mis loeks lugude info plaadi enda pealt välja ja tekitaks kohe automaatselt A4 paberile väljatrükitava lugude nimekirja sobiva teksti suurusega.
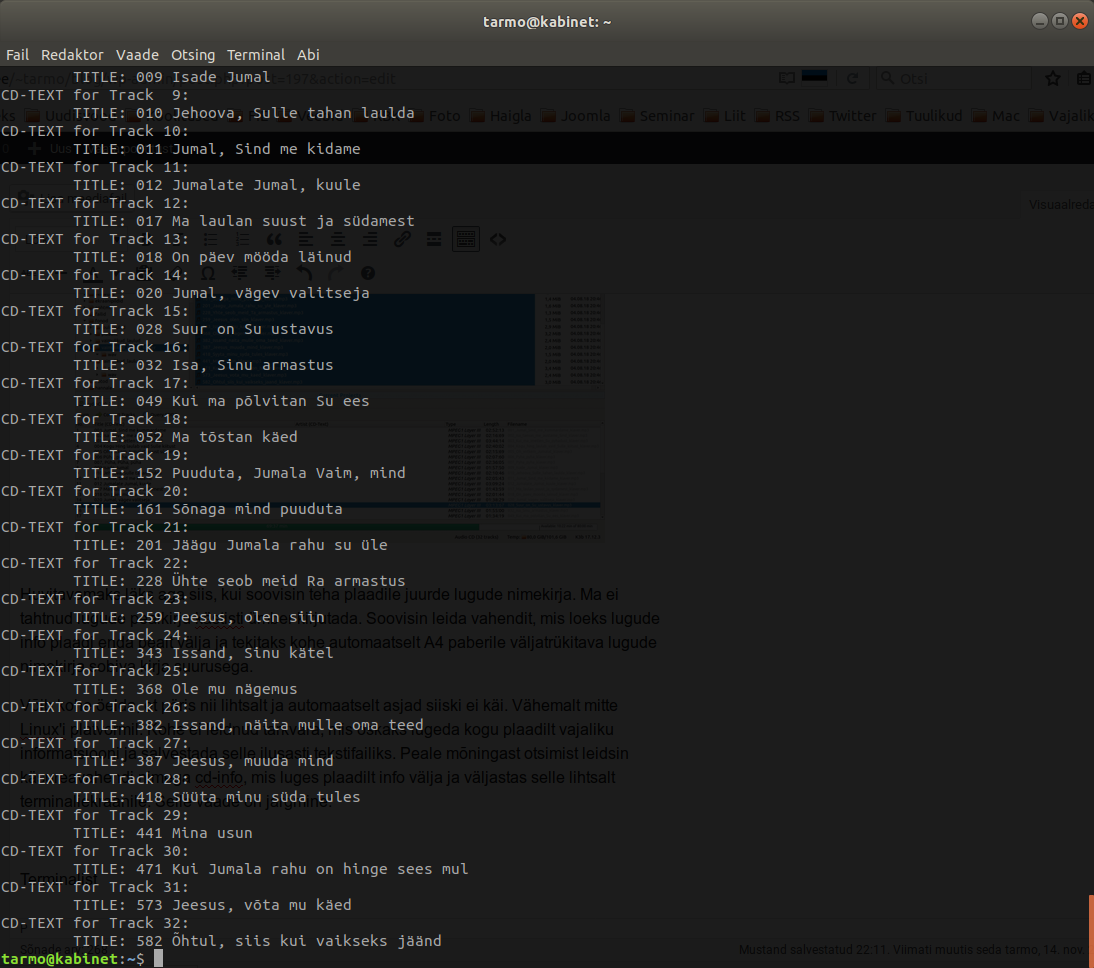
Võib kohe öelda, et päris nii lihtsalt ja automaatselt asjad siiski ei käi. Vähemalt mitte Linux’i platvormil. Kohe ei leidnud tarkvara, mis oskaks lugeda kogu plaadilt vajaliku informatsiooni ja salvestada selle ilusasti tekstifailiks. Peale mõningast otsimist leidsin käsureavahendi nimega cd-info, mis luges plaadilt info välja ja väljastas selle lihtsalt terminaliekraanile. Selle vaade on järgmine:
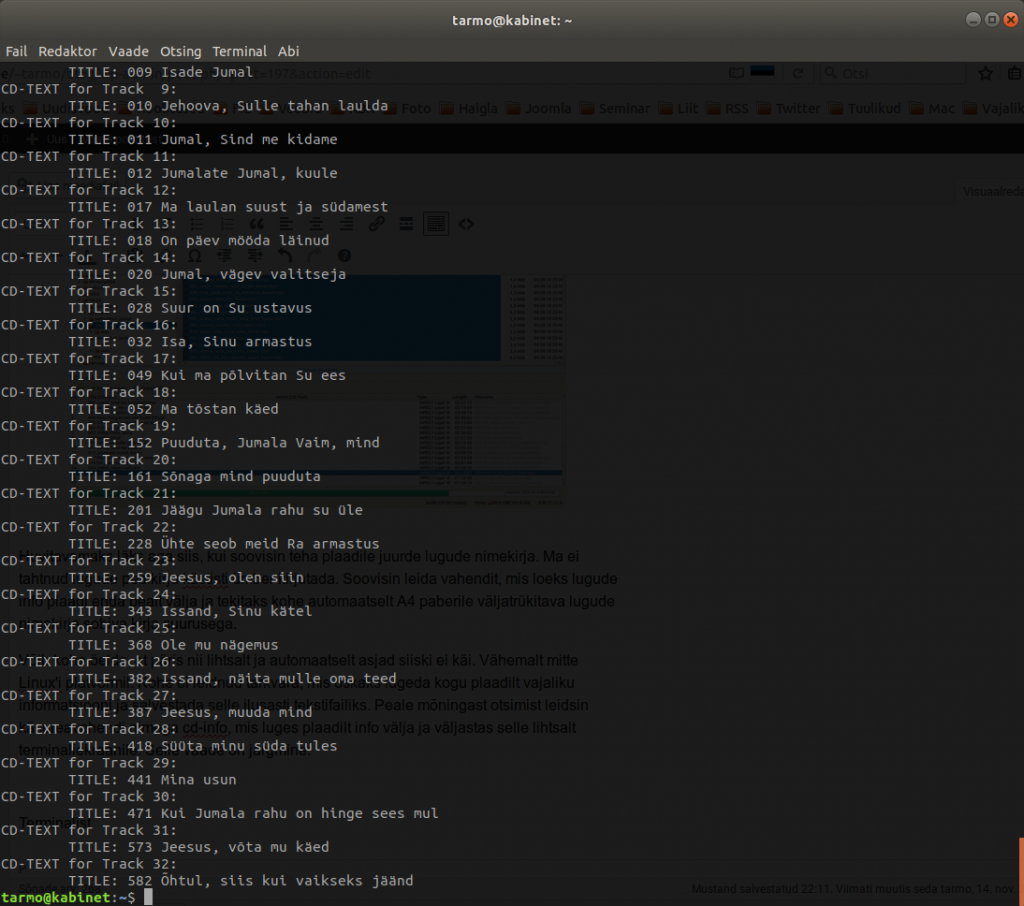
Terminalist saab teksti kopeerida – aga terminalis saab ka kasutada käsku
|
|
cd-info > cd-plaadi-lugude-nimekiri.txt |
mis loob kohe tekstifaili, milles on olemas kogu tekst, mille cd-info väljastas. Seda tekstifaili saab juba igasuguste tavaliste tekstiredaktoritega redigeerida, et kustutada mittevajalik ja alles jätta vaid vajalik. Tekstist ülearuse kustutamine on oluliselt lihtsam ja kiirem tegevus, kui käsitsi kõigi laulude nimede kirjutamine.
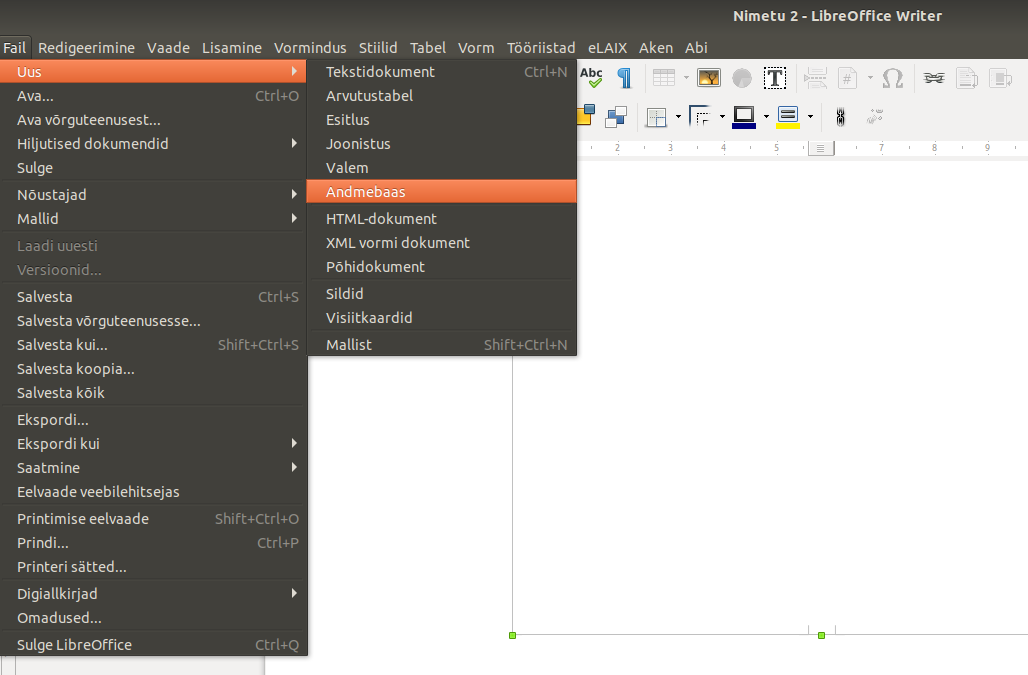
Otsides head vahendit, mis looks CD-plaadi karbi sisse pandavat õiges suuruses ja tavaliselt paberilt välja lõigatavat etiketti, jäin lõpuks pidama LibreOffice Writeri siltide loomise abilise juurde. On olemas spetsiaalseid CD-etikettide loomise vahendeid (näiteks gLabels), kuid need sageli eeldavad, et ka prinditakse spetsiaalsele paberile või valmis kleepsupaberile. Mina aga tahtsin saada väga lihtsat ruudukujulist etiketti, millel oleks peal servajooned, et oleks lihtne pärast tavaliselt A4 paberilt välja lõigata. Selleks sobiski kõige paremini LibreOffice sildilooja. Alusta tuleb uue dokumendi loomist menüüde Fail → Uus → Sildid abil ja seejärel avaneb dialoogiaken, kust saab valida standardi, millist silti/etiketti just soovitakse luua. LibreOfficega on kaasas terve hulk erinevate tootjate poolt etiketistandardite põhju, kus on juba eeldefineeritud kõik vajalikud mõõdud. Järgmised kaks ekraanipilti näitavad seda, kuidas valida sobivat etiketti.
Seejärel avaneb dialoogiaken, kust saab valita erinevate tootjate erinevaid etikettide ja siltide põhju.
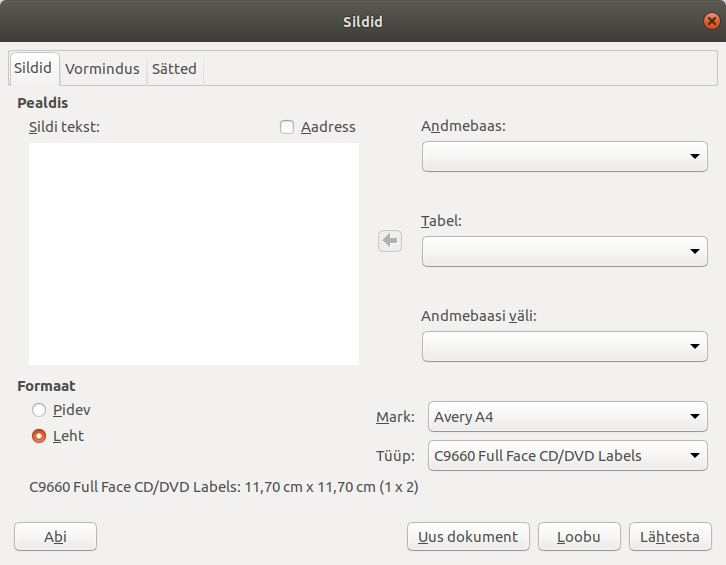
Kui oli valitud õige mark ja tüüp, siis tuleks vajutada “Uus dokument”, mis loob tühja dokumendi, kus on vaid raamid kastidele, kuhu sisse tuleb paigutada vajalik tekst. Need raamid on tehnilises mõttes objektid, mille omadusi saab muuta vastavalt soovidele: lisada taustavärve või panna ümber raamid; luua kas ühe-, kahe- või kolmeveeruline lugude nimekirja loend, mängida kirjaviisiga ja teksti värviga jne… Ainus, mida muuta ei tasu, on kasti enda mõõtmed ja asukoht lehel, kuna need on eeldefineeritud vastavaks CD-karbi mõõtudele ja paigutatud nii, et kindlasti kõik nähtav jääks.
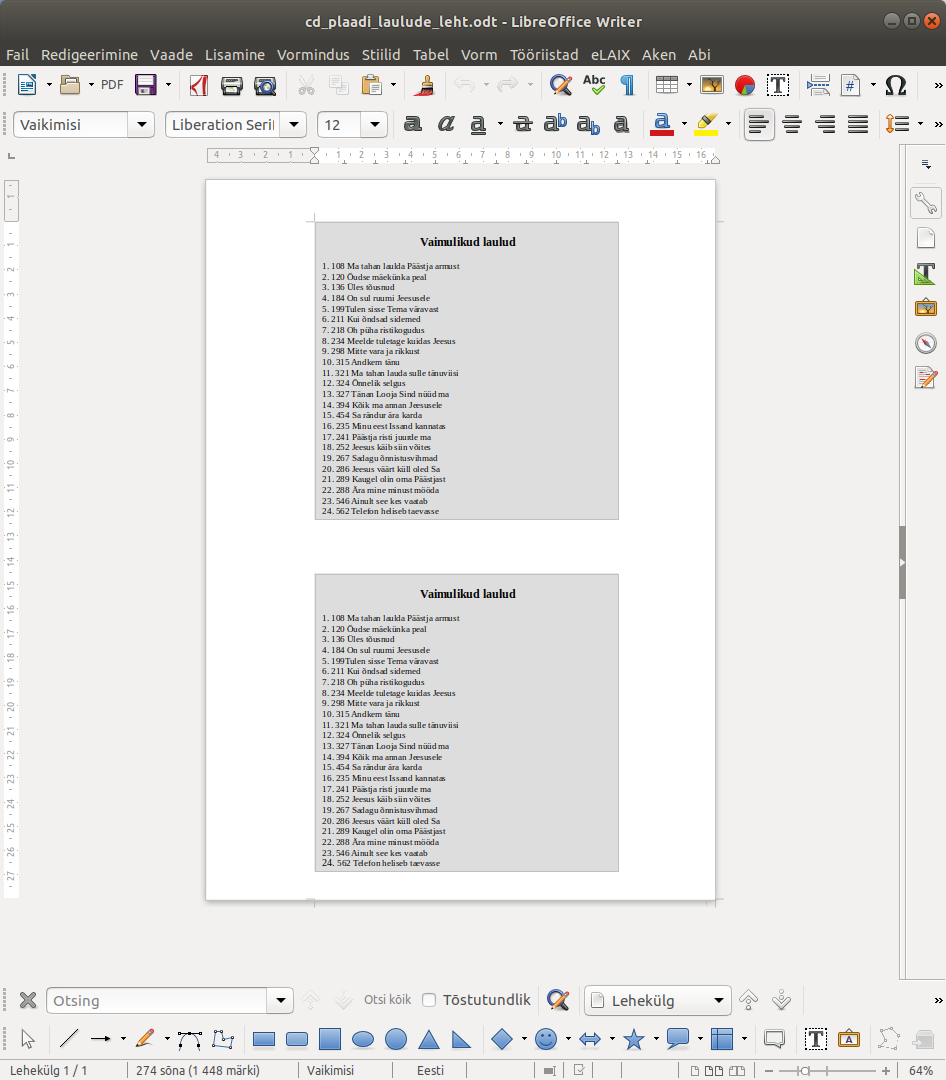
Kui vajalik tekst oli sisse toodud ja kujundatud, sai lõpptulemus järgmine:
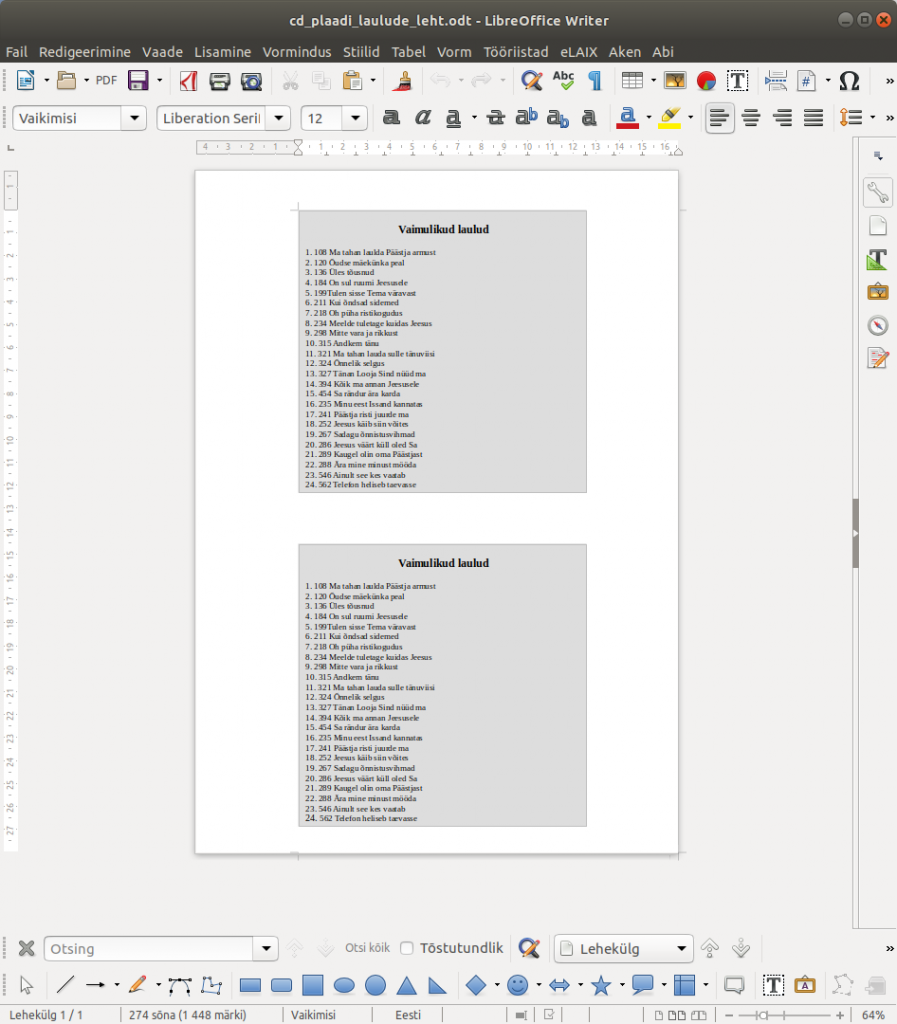
Tekstiredaktoris on lihtne muuta teksti suurust, paigutada pikema nimekirja korral laulud kahte veergu või teha mida just vaja, et kogu nimekiri ühele etiketile tervikuna ära mahuks. Seda lehte oli juba lihtne välja printida ja siis halli ala serva pidi õiges suuruses etiketid välja lõigata. Need sobisid täpselt cd-plaadi karbi sisse panemiseks.
Eks ta ole – kuna mul polnud pikalt vajadust sellist cd-plaadi etiketti teha, olin täiesti unustanud, kuidas see üldse käib. Nüüd sai uuesti metoodika meelde tuletatud. Kindlasti on minu viimasest plaadi tegemisest ka piisavalt palju aega möödas – selle aja jooksul on ka tehnilised vahendid muutunud. Nii tuligi sisuliselt uuesti õppida. Sel korral sai ka kirja pandud, et kui jälle vaja teha on, siis on ehk lihtsam järgi vaadata, kuidas see käib. Ja ehk on kellelgi veel sellest kasu.
PS. Linux-maailmas on tarkvara paigaldamine ise tehtud väga lihtsaks. Rohkem võtab aega uurimine, millist tarkvara just tahaks, aga installeerimiseks kasutan mina terminali-aknas käsku
|
|
sudo apt-get install <programminimi> |
Aga loomulikult on olemas ka graafiline vahend, mida viimasel ajal nimetatakse “Tarkvarakeskuseks” ja kust saab otsida tarkvara, vaadata tarkvara kirjeldust (enamasti küll inglise keeles) ja kui tundub, et see on sobiv tarkvara, siis ka kohe paigaldada. Mina vaatan tavaliselt enne veel veebist kasutajate arvamusi ja alles seejärel otsustan, kas rakendus on mulle loodetavasti sobiv või mitte.